Kafka - Introduction
1. What is Apache Kafka?
Apache Kafka is a distributed event streaming platform capable of handling trillions of events per day. It is designed to be fault-tolerant, scalable, and durable, providing a high-throughput messaging system for real-time data processing and integration.
2. Key Features of Kafka
- Scalability: Kafka can scale horizontally by adding more brokers to a cluster, allowing it to handle massive data volumes.
- Durability: Kafka stores data durably on disk, ensuring message persistence and reliability.
- Fault Tolerance: Kafka's replication and partitioning capabilities provide high availability and fault tolerance.
- High Throughput: Kafka is optimized for high throughput, making it suitable for real-time data processing.
- Low Latency: Kafka delivers messages with low latency, ensuring timely data delivery.
- Stream Processing: Kafka Streams API enables real-time stream processing directly on Kafka topics.
3. Kafka Architecture
Kafka's architecture is designed around a distributed system of brokers, topics, partitions, producers, and consumers. This architecture provides fault tolerance, scalability, and high throughput for data streaming.
3.1. Brokers
Kafka brokers are servers that store and manage message data. Each broker handles multiple partitions and replicas, ensuring data distribution and redundancy.
3.2. Topics and Partitions
Topics are categories or feeds to which messages are published. Each topic is divided into partitions, allowing Kafka to parallelize message processing and storage.
3.3. Producers
Producers are clients that publish messages to Kafka topics. They determine the partition to which each message is sent, allowing for data organization and scalability.
3.4. Consumers
Consumers are clients that subscribe to Kafka topics and process incoming messages. Consumers can belong to consumer groups, enabling load balancing and parallel processing.
Kafka Architecture Diagram
The following diagram illustrates the architecture of a Kafka cluster, including brokers, topics, partitions, producers, and consumers.

4. Kafka Use Cases
4.1. Real-Time Analytics
Kafka is widely used for real-time analytics, enabling organizations to process and analyze data as it is generated, providing immediate insights and decision-making capabilities.
Example Use Case
A retail company uses Kafka to collect and analyze customer purchase data in real time, optimizing inventory management and enhancing customer experience.
4.2. Data Integration
Kafka acts as a central hub for data integration, connecting various systems and applications with real-time data streams. It enables seamless data exchange and processing across an organization.
Example Use Case
An e-commerce platform uses Kafka to integrate data from multiple services, such as inventory, payments, and user activity, ensuring consistency and reliability.
4.3. Event-Driven Microservices
Kafka is ideal for event-driven microservices architectures, allowing services to communicate through events and decouple dependencies, leading to more scalable and maintainable systems.
Example Use Case
A financial institution leverages Kafka to build microservices that handle transactions, account updates, and notifications in an event-driven manner.
5. Kafka Stream Processing
Kafka provides stream processing capabilities through its Kafka Streams API, allowing developers to process and analyze data streams in real-time. Kafka Streams is a lightweight library that can be integrated into Java applications to perform operations like filtering, aggregation, and joining on data streams.
5.1. Stream Processing Architecture
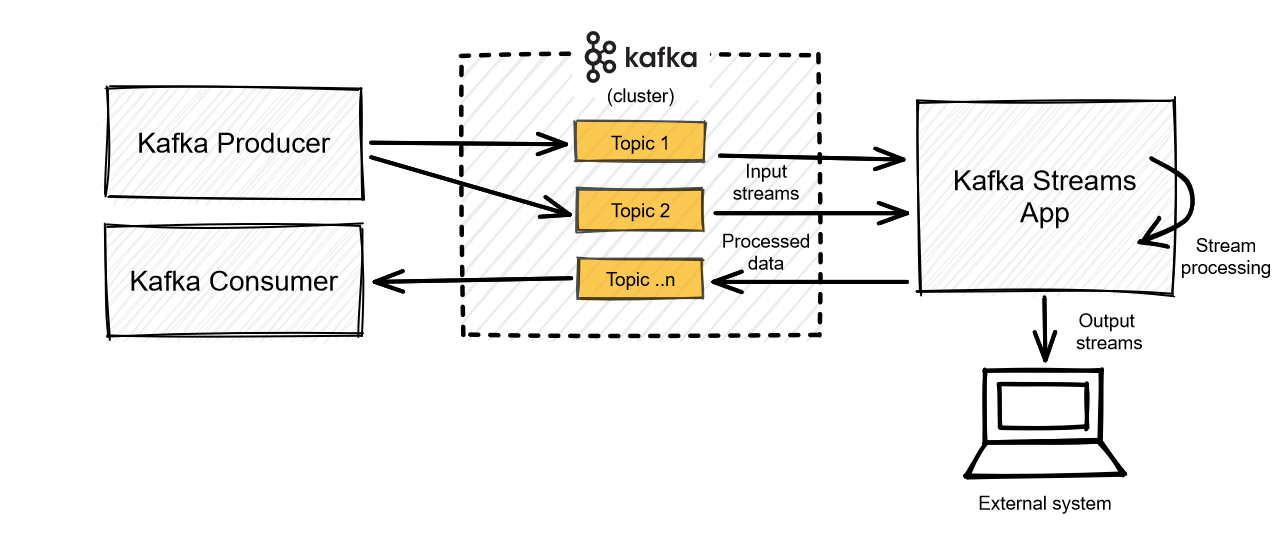
Kafka Streams processes data records from Kafka topics and produces output to other topics. It provides features such as stateful processing, windowing, and event-time processing, enabling complex real-time analytics and transformations.
Kafka Stream Processing Schema
The following diagram illustrates a typical Kafka Streams processing pipeline, showcasing the flow of data from source topics, through processing logic, to destination topics.
6. Notes and Considerations
When implementing Kafka, consider factors such as data volume, throughput requirements, fault tolerance, and integration with existing systems. Proper configuration and monitoring are essential to ensure optimal performance and reliability.